01. O que é Apache Hop?
O Apache Hop (Hop Orchestration Platform) é uma plataforma visual open source para construção de pipelines de ETL (Extract, Transform, Load).
Ela permite a orquestração de dados entre diversas fontes com interface intuitiva, baseada em “pipelines” e “workflows”.
Principais recursos:
- Interface 100% visual baseada em componentes;
- Totalmente modular e extensível;
- Suporte a transformações complexas sem código.
02. Planejando seu fluxo ETL com Apache Hop
Antes de começar seu ETL com Apache Hop, defina:
- Fonte de dados (banco, planilha, API);
- Transformações desejadas (limpeza, filtro, join);
- Destino dos dados (data warehouse, banco, csv);
Um bom planejamento evita retrabalho e deixa o pipeline mais limpo.
Entendendo cada uma das etapas do ETL com Apache Hop
1. Text file input no ETL com Apache Hop
A transformação Text file input é a porta de entrada para dados em formato texto (CSV, TXT, etc). Ela permite configurar o carregamento de múltiplos arquivos com padrões diferentes, como ilustrado nas imagens:
File:
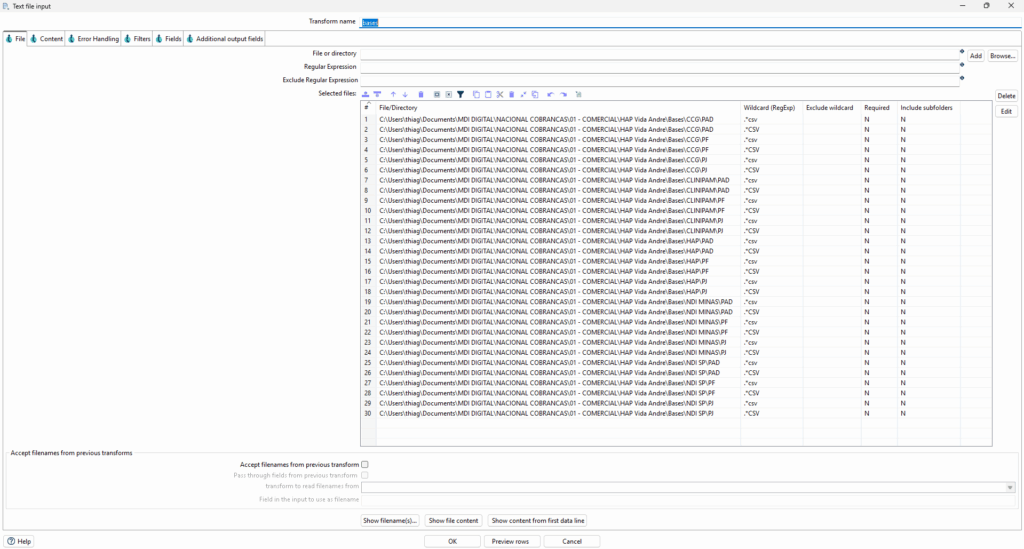
- Adiciona múltiplos arquivos e define o filtro por extensão (
*.CSV). - Cada caminho de diretório pode representar uma carteira ou tipo de contrato.
Content:
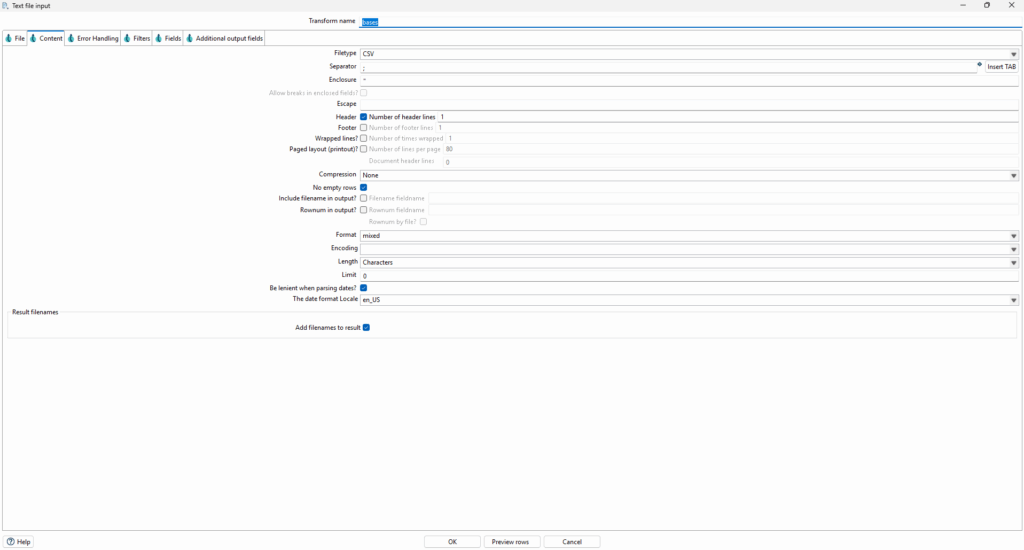
- Define separador (
;) e formato (CSV). - Permite configurar se existe cabeçalho, tipo de compressão, charset e layout.
Fields:

- Define o schema dos dados, com tipo, posição e formato de cada campo (como
nu_contrato,dias_atraso,data_vencimento).
Additional output fields:

- Permite registrar metadados sobre o arquivo lido, como:
Short filenamePathExtensionURI
Esses campos são úteis para rastreabilidade ou classificação de dados no processo.
2. Step: Replace in String (Exemplo real)

Nesta configuração, o campo carteira está sendo limpo com a seguinte lógica:
- Campo de entrada (In stream field):
carteira - Busca (Search):
. - Substituição (Replace with):
- - Use RegEx:
N(não usa expressão regular)
🔍 Isso significa que toda ocorrência do ponto (.) será substituída por traço (-), uma prática comum ao padronizar nomes de arquivos, IDs ou pastas.
Exemplo prático:
- Valor original:
NDI.SP.PAD - Resultado após a transformação:
NDI-SP-PAD
💡 Dica:
Se quiser remover o ponto ao invés de trocar por hífen, deixe o campo Replace with em branco.
3. Strings cut

Essa etapa é usada para recortar partes específicas de uma string com base em posições fixas, como se estivesse usando substring().
Configuração apresentada:
| Campo de entrada | Campo de saída | De (posição) | Até (posição) |
|---|---|---|---|
carteira | data_base | 13 | 23 |
carteira | mes_base | 16 | 23 |
🔍 Objetivo:
Extrair partes da string carteira que representam informações temporais, como data e mês, com base na posição dos caracteres.
Exemplo prático:
- Valor do campo
carteira:CCG.PJ.BASE_2024-06 - Resultado:
data_base→2024-06mes_base→06
💡 Dica:
As posições são baseadas em index 1, ou seja, o primeiro caractere da string é posição 1 (não 0 como em muitas linguagens).
- Use esse método apenas quando as posições forem sempre fixas. Para estruturas mais dinâmicas, use Split Fields ou Regex Evaluation.
4. Replace base (Replace in string)

Nesta etapa, o objetivo é limpar e padronizar campos com caracteres inadequados antes da transformação e carga. Isso garante a integridade dos dados para uso posterior.
Configurações visíveis:
| Campo | Substituir Search | Por Replace with |
|---|---|---|
cpf/cnpj | = | (nada) |
cpf/cnpj | " | (nada) |
valor | " | ' |
contrato | " | (nada) |
data_base | . | / |
data_base | - | / |
mes_base | - | / |
Objetivo de cada substituição:
cpf/cnpj: Remove caracteres estranhos como = ou aspas, comuns em arquivos CSV exportados de Excel ou sistemas legados.
valor: Substitui aspas por apóstrofo'para evitar quebra de leitura numérica.contrato: Elimina aspas, limpando o valor.data_baseemes_base: Converte.e-para/para padronizar as datas no formatodd/MM/yyyyouMM/yyyy.
💡 Dica prática:
Se você estiver preparando os dados para escrita em banco de dados ou geração de relatório, padronizar datas e campos de chave como CPF/CNPJ é essencial para evitar erros de validação.
5. JavaScript (Classificação por tipo de arquivo)

Essa etapa usa JavaScript interno do Apache Hop para:
- Normalizar caminhos de diretório;
- Extrair o sufixo do nome da base;
- Classificar o tipo da base como PF, PJ, VC ou OUTRO.
🔍 Código explicando cada parte:
javascriptCopiarEditar// Remove espaços e normaliza a barra
var caminho = tipo.trim().replace(/\\/g, "/");
// Extrai o último segmento após a última barra
var partes = caminho.split("/");
var sufixo = partes[partes.length - 1];
// Classificação baseada no final do caminho
if (sufixo == "PJ") {
tipo_classificado = "PJ";
} else if (sufixo == "PF") {
tipo_classificado = "PF";
} else if (sufixo == "PAD") {
tipo_classificado = "VC";
} else {
tipo_classificado = "OUTRO";
}
📌 Saídas geradas:
caminho– o caminho original limpo;partes– array com segmentos do caminho;sufixo(renomeado paratipo) – resultado da classificação:"PJ","PF","VC"ou"OUTRO".
💡 Dica de melhoria:
Você pode encapsular essa lógica em um “User Defined Java Class” se quiser manter seu código reutilizável e com mais segurança de tipagem.
6. Number range (Faixa de atraso)

Essa transformação é utilizada para classificar um campo numérico em categorias, com base em faixas definidas de valores.
⚙️ Configuração apresentada:
- Input field:
dias_atraso - Output field:
faixa_atraso_bases - Default (sem faixa correspondente):
Maior que um ano
📊 Faixas configuradas:
| Limite Inferior | Limite Superior | Valor de saída |
|---|---|---|
| -9999 | 4 | Menor que 5 |
| 5 | 11 | 5 a 10 |
| 11 | 31 | 11 a 30 |
| 31 | 61 | 31 a 60 |
| 61 | 91 | 61 a 90 |
| 91 | 121 | 91 a 120 |
| 121 | 151 | 121 a 150 |
| 151 | 181 | 151 a 180 |
| 181 | 366 | 181 a 365 |
| Acima de 365 | – | Maior que um ano (default) |
✅ Aplicações práticas:
- Permite segmentar clientes por perfil de cobrança;
- Facilita filtros condicionais em “Switch/Case” ou relatórios;
- Pode ser usada para aplicar mensagens diferentes por e-mail/SMS.
💡 Dica:
Evite sobreposição nas faixas (ex: 11-31 e 31-61) para garantir precisão e evitar duplicidades no mapeamento.
7. Table input (Leitura do banco de dados)

Essa etapa é usada para consultar diretamente uma tabela ou view de um banco de dados relacional, retornando os dados como input para o fluxo ETL.
⚙️ Configuração atual:
- Conexão:
DBNNC(nome da conexão configurada previamente) - Consulta SQL:
sqlCopiarEditarSELECT
data_base,
mes_base,
remessa,
nu_obrigacao,
vencimento,
valor,
dias_atraso,
contrato,
empresa_plano,
tipo,
filial,
faixa_atraso_bases,
cpf_cnpj
FROM hapvida_pa_fixa.f_bases
WHERE data_base >= NOW() - INTERVAL '3 months' -- Filtro para os últimos 3 meses
ORDER BY data_base;
🔍 Objetivo da consulta:
- Buscar registros recentes (últimos 3 meses) da tabela
f_bases; - Trazer colunas já tratadas como
faixa_atraso_bases,dias_atrasoetipo; - Evitar sobrecarga de dados antigos ou irrelevantes para ações de cobrança.
✅ Boas práticas:
- Use
LIMITse o volume for muito alto e você estiver testando; - Utilize comentários (
--) para documentar filtros críticos; - Prefira views otimizadas com índices quando possível.
8. Merge rows (diff)

Essa etapa é usada para comparar duas versões de um mesmo conjunto de dados — pois geralmente o “banco” (dados atuais salvos) versus “staging” (dados novos) — e identificar diferenças.
⚙️ Configuração:
- Reference rows origin:
Select dw→ Dados do banco (referência) - Compare rows origin:
Select stg→ Dados novos (provenientes do processamento) - Flag field name:
flagfield→ Campo de saída com o tipo de alteração
🧩 Chaves de comparação (Keys to match):
Campos usados para identificar registros únicos:
data_base,mes_base,remessa,nu_obrigacao,cpf_cnpj, etc.
🧪 Valores comparados (Values to compare):
Campos cujas alterações serão detectadas:
- Ex.:
valor,dias_atraso,empresa_plano,faixa_atraso_bases
🏷️ Saídas possíveis do campo flagfield:
"identical"→ Sem alterações;"new"→ Registro novo na base de staging;"changed"→ Algum campo de valor mudou;"deleted"→ Presente no banco, mas ausente na base nova (opcional).
💡 Aplicações comuns:
- Evitar sobrescrita desnecessária no banco;
- Acionar lógicas diferentes no fluxo (
Switch/Case); - Gerar logs ou auditoria com registros alterados.
9. Switch / Case (Direcionamento por status de atualização)

Essa etapa é usada para encaminhar os dados para diferentes caminhos, com base no valor de um campo de controle — neste caso, o flagfield gerado pelo Merge rows (diff).
⚙️ Configuração:
Field name to switch: flagfield
- Valores de decisão (Case values):
"new"→ encaminha para Table output (inserção de novos registros)"changed"→ encaminha para Update (atualização dos existentes)
✅ Como funciona na prática:
- Cada registro será roteado automaticamente conforme seu status:
- Se for novo → insere no banco.
- Se tiver mudado → executa atualização.
- Outros (como
"identical") podem ser ignorados ou tratados no Default target transform.
💡 Dica:
Use Switch/Case sempre que quiser ramificar a lógica do seu pipeline com base em valores dinâmicos, mantendo o fluxo limpo e modular.
10. Finalizando o fluxo ETL: Etapas de gravação
Step: Table Output (Inserção de novos registros)

Esta transformação insere novos dados no banco, mais especificamente na tabela stg_bases, no schema hapvida_pa_fixa.
⚙️ Configuração:
- Conexão:
DBNNC - Target table:
stg_bases - Commit size:
1000(ótimo para desempenho sem travar o banco) - Specify database fields: ✔️ (garante o mapeamento direto e explícito)
📝 Mapeamento:
Todos os campos são inseridos diretamente conforme vieram do fluxo — por exemplo:
valor,dias_atraso,empresa_plano,faixa_atraso_bases, etc.
✅ Ideal para dados que ainda não existem na base.
Step: Update (Atualização de dados existentes)

Essa etapa atualiza os registros que já existem na stg_bases, comparando pelas chaves:
🔑 Chaves de busca:
nu_obrigacaocontratomes_basetipo
Esses campos definem unicamente cada linha a ser atualizada.
🔁 Campos atualizados:
valor,dias_atraso,empresa_plano,faixa_atraso_bases, entre outros.
💡 Atualizações são ideais para manter os dados atualizados sem duplicar registros.
Com isso, o ciclo ETL está completo: leitura de base, limpeza, classificação, comparação e persistência inteligente.
Conclusão
Apache Hop é uma ferramenta robusta e acessível para quem busca automatizar processos de ETL com segurança e visibilidade. Com um pouco de planejamento e organização, é possível montar pipelines complexos de forma intuitiva.
Experimente criar seu primeiro fluxo hoje e descubra como o Apache Hop pode revolucionar o tratamento dos seus dados.