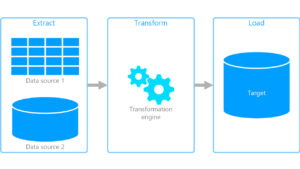
ETL Python (Extract, Transform, Load) é um processo utilizado na integração de dados que envolve a extração de dados de diversas fontes, transformação desses dados de acordo com as necessidades do usuário e o carregamento desses dados em um local de destino.
O Python é uma linguagem de programação amplamente usada em ETL devido à sua facilidade de uso, versatilidade e eficiência.
O Pandas é uma biblioteca Python de análise de dados que oferece ferramentas poderosas para realizar operações de ETL.
Algumas das principais funções do Pandas em ETL incluem:
Extração de dados
O Pandas pode ler dados de uma ampla variedade de fontes, incluindo arquivos:
- CSV;
- Excel;
- SQL;
- JSON;
- HTML.
Ele pode extrair dados de uma única fonte ou de várias fontes simultaneamente.
Transformação de dados
O Pandas oferece uma ampla variedade de funções para transformar dados, incluindo a:
- Limpeza e formatação de dados;
- Agregação e o agrupamento de dados,
- Eliminação de duplicatas;
- Criação de novas colunas e cálculos.
Carregamento de dados
O Pandas pode salvar os dados transformados em diversos formatos, como:
- CSV;
- Excel;
- SQL;
- JSON;
- HTML.
Ele também pode carregar os dados diretamente em um banco de dados SQL.
Para utilizar o Pandas em ETL, basta importar a biblioteca e começar a utilizar suas funções para extrair, transformar e carregar dados.
É uma maneira rápida e fácil de realizar operações de ETL em Python.
Arquivo exemplo
Para fazer nosso processo de ETL vou utilizar um arquivo .xlsx de Metas por Vendedor.

Essa tabela possui 26 colunas, sendo uma delas com o código de cada vendedor e 24 colunas com datas de janeiro de 2017 até dezembro de 2018 e uma colunas total no final da tabela.
Já nas linhas, temos 17 linhas sendo a primeira o cabeçalho, as próximas 3 linhas estão em branco, a linhas 5 possui os títulos das colunas, da colunas 6 até a 16 temos os valores da metas e por final temos um última linha somando o totla.
Kaggle
Nesse exemplo vou utilizar o Kaggle para trabalhar nessa ETL.
Kaggle é uma comunidade on-line de cientistas de dados e machine learning, fundada em 2010.
O objetivo do Kaggle é fornecer uma plataforma para que cientistas de dados possam encontrar e compartilhar conjuntos de dados, colaborar em projetos e competir em desafios de aprendizado de máquina.
O Kaggle oferece uma ampla variedade de conjuntos de dados, de diferentes áreas, incluindo finanças, saúde, esportes, jogos, tecnologia e muitas outras.
Os usuários podem baixar esses conjuntos de dados gratuitamente para uso em seus próprios projetos e análises.
Além disso, o Kaggle também oferece competições de aprendizado de máquina, onde os usuários podem competir para criar o modelo mais preciso para resolver um problema específico.
Essas competições geralmente envolvem empresas e organizações que estão procurando soluções para problemas específicos de análise de dados.
O Kaggle também oferece uma plataforma de aprendizado de máquina baseada em nuvem, chamada Kaggle Kernels, que permite que os usuários escrevam, execute e compartilhem códigos de aprendizado de máquina diretamente em seu navegador, sem a necessidade de configurar uma infraestrutura de computação separada.
Em resumo, o Kaggle é uma plataforma aberta e colaborativa para a comunidade de cientistas de dados e machine learning, que oferece uma variedade de recursos e ferramentas para ajudar a desenvolver habilidades em análise de dados e aprendizado de máquina.
Importanto o arquivo .xlsx para o Kaggle
Para fazer o tratamento da tabela de metas iremos utilizar a biblioteca Pandas que já vem importada quando você cria um novo notebook.
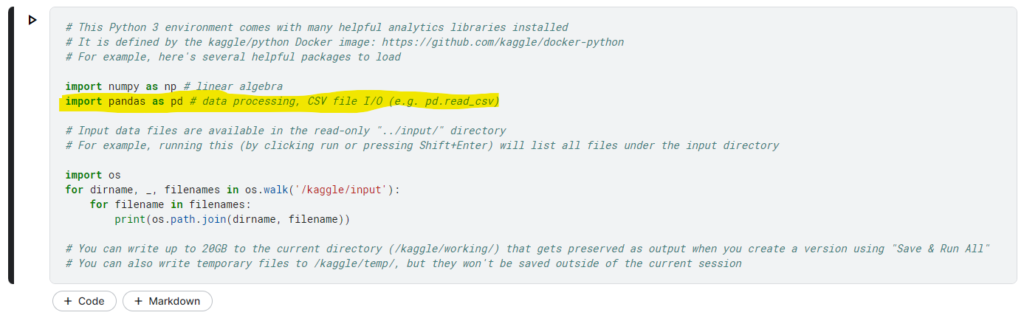
Para confirmar a instalação da biblioteca é só apertar no botão play no canto superior esquerdo, ou então apertar Shift + Enter dentro do bloco do notebook.
Em seguida iremos fazer o upload do nosso arquivo dentro do notebook que nos criamos.
Para isso clique no botão Upload data no lado direito superior do seu notebook.
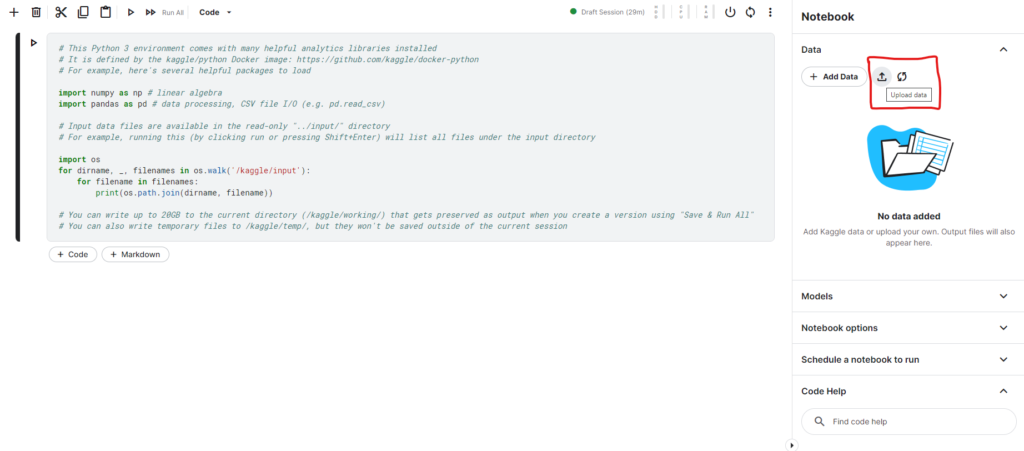
Após importar o arquivo o mesmo deve aparecer como Input no mesmo lugar onde você clicou para fazer o upload do arquivo.
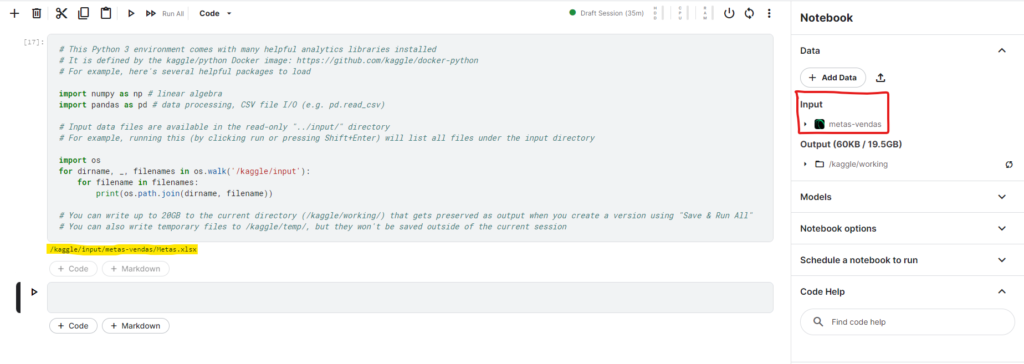
Na sequência rode novamente o bloco onde estão o import das bibliotecas e o Kaggle irá criar um caminho para você utilizar seu arquivo dentro do notebook.
Iniciando o processo de ETL Python
1. Analisando o arquivo
Para fazer isso iremos utilizar o seguinte código:
dados = pd.read_excel('/kaggle/input/metas-vendas/Metas.xlsx')
dadosComo o próprio nome já diz esse código ira fazer a leitura da nossa planilha.
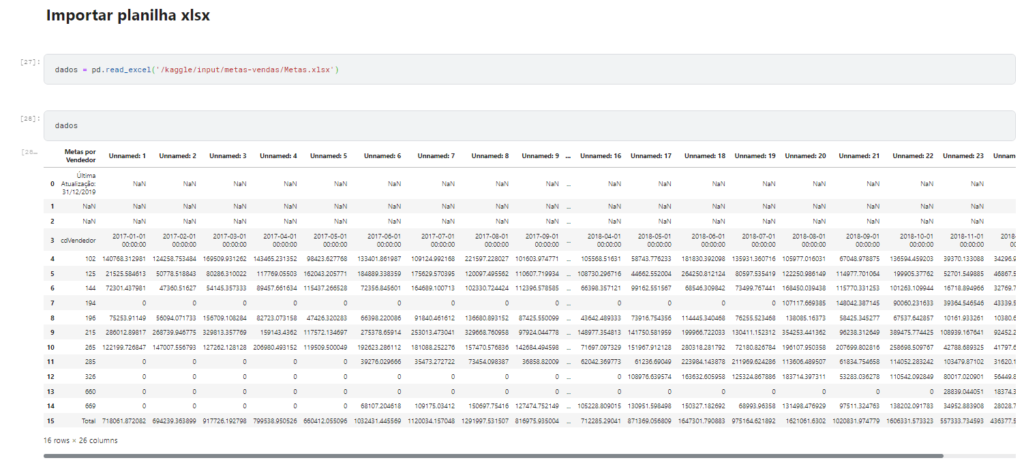
Olhando para o arquivos podemos perceber que temos as 3 principais linhas com NaN, ou seja, nulo. E a última linhas temos o Total que também não iremos utilizar.
2. Removendo linhas
Para resolver esse problema vamos remover essas 3 primeiras linhas com o seguinte comando:
dados = dados.drop([0,1,2,15])Assim teremos o seguinte resultado.
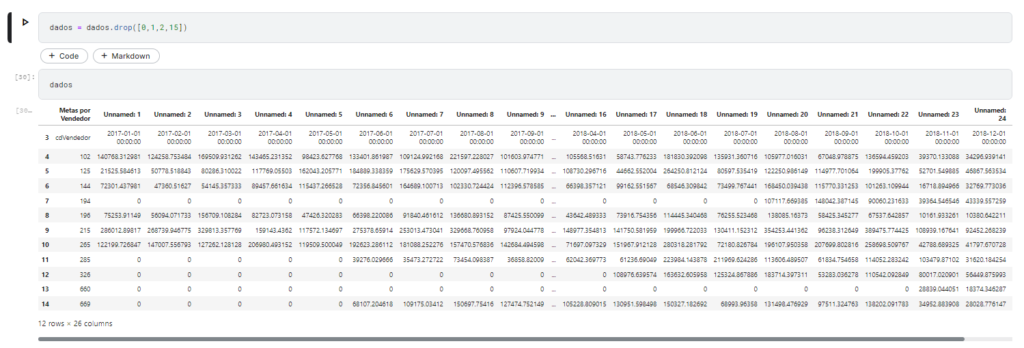
A próxima etapa iremos tranformar a primeira linha da tabela onde temos os nossos títulos das colunas em cabeçalhos.
3. Usar primeira linha como cabeçalho
Usaremos então o seguinte comando:
dados = dados.rename(columns=dados.iloc[0]).drop(dados.index[0])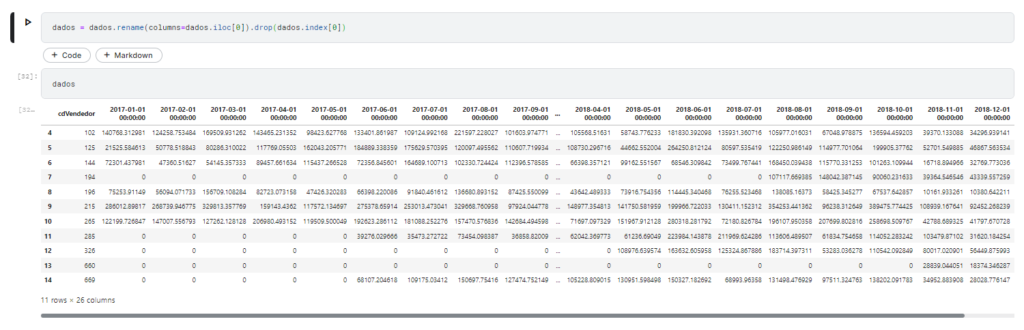
4. Removendo colunas
Além da linha 15 que continha o total somado das metas, temos também uma coluna no final da tabela que também tem a soma de cada umas das linhas.
Para remover essa colunas é simples:
dados = dados.drop('Total', axis=1)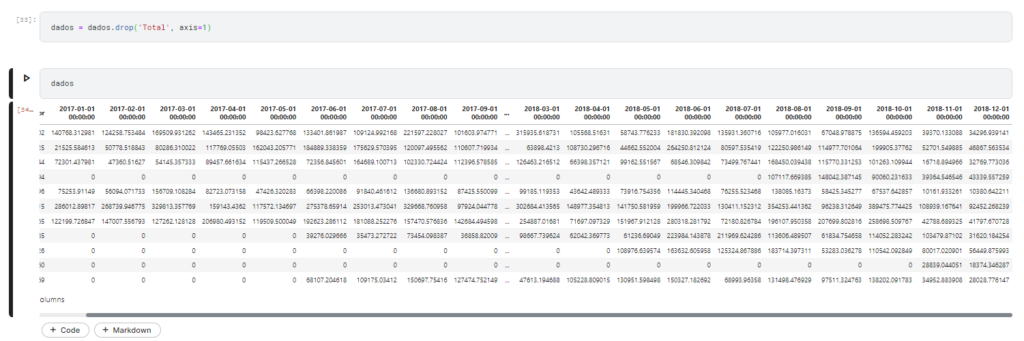
5. Tranformando colunas em linhas
Transformar colunas de datas em linhas pode ser útil em algumas situações, por exemplo, quando se deseja visualizar a evolução de valores ao longo do tempo, em que cada linha representa uma determinada data e cada coluna representa um tipo de dado ou categoria.
Além disso, essa transformação pode facilitar o agrupamento e a análise de dados por período, permitindo a criação de gráficos de tendência e a identificação de padrões sazonais.
No entanto, é importante avaliar cuidadosamente a necessidade e a relevância desse tipo de transformação de acordo com o objetivo do projeto de análise de dados.
Para fazer essa tranformação usaremos o seguinte codigo:
dados = dados.melt(id_vars=['cdVendedor'], var_name='Data', value_name='Valor')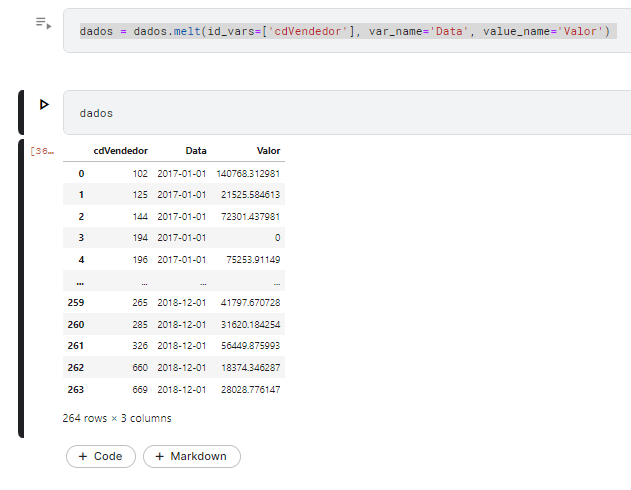
Tranformando tipo de coluna
E agora para finalizar a parte de extração e tranformação desse arquivo iremos tranformar a coluna “Data” no tipo datetime, e a coluna “Valor” no tipo float (Escritos com ponto decimal e podem ser positivos e negativos).
Para isso usaremos esses dois códigos.
dados['Valor'] = dados['Valor'].astype('float')dados['Data'] = pd.to_datetime(dados['Data'])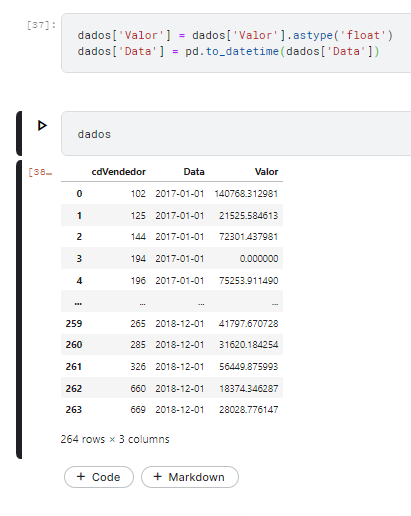
Por fim podemos exportar o arquivo .xlsx e importar ele no Power BI por exemplo sem precisar sobrecarregar o BI com essas tranformações.
Para exportar utilize o seguinte comando.
6. Exportando arquivo final .xlsx
dados.to_excel('metas.xlsx', index=False)Caso tenha ficado com alguma dúvida fico a dispoisção para trocar uma ideia.